Deep Learning Recommendation Models (DLRM)
Paper link: https://arxiv.org/abs/1906.00091
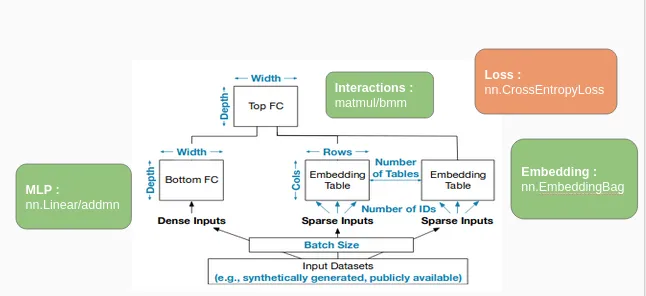
Model workflow:
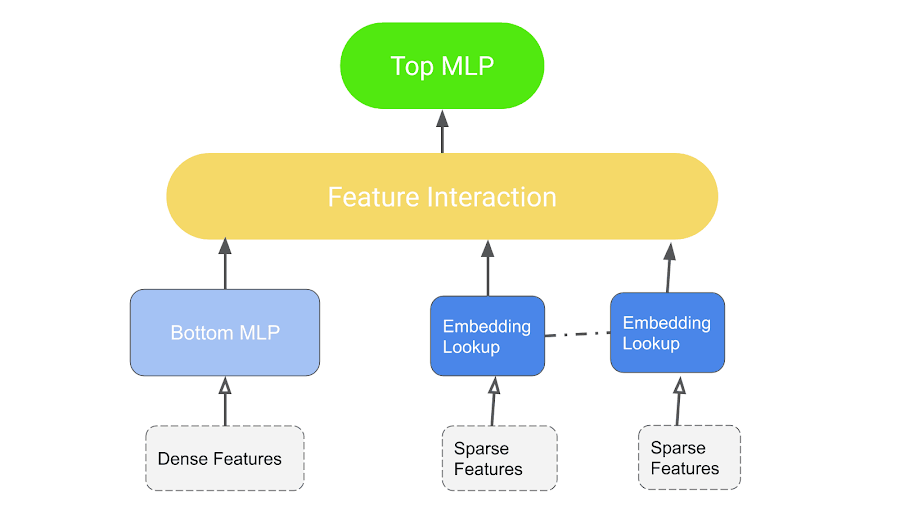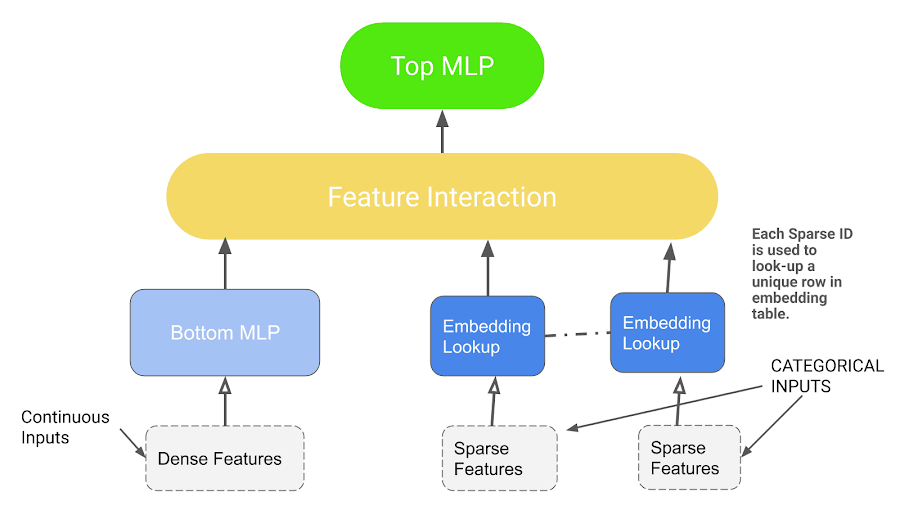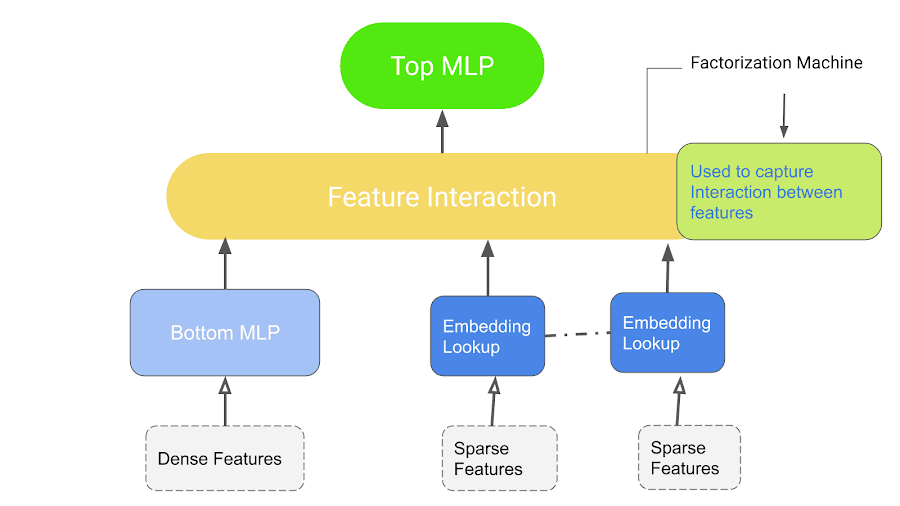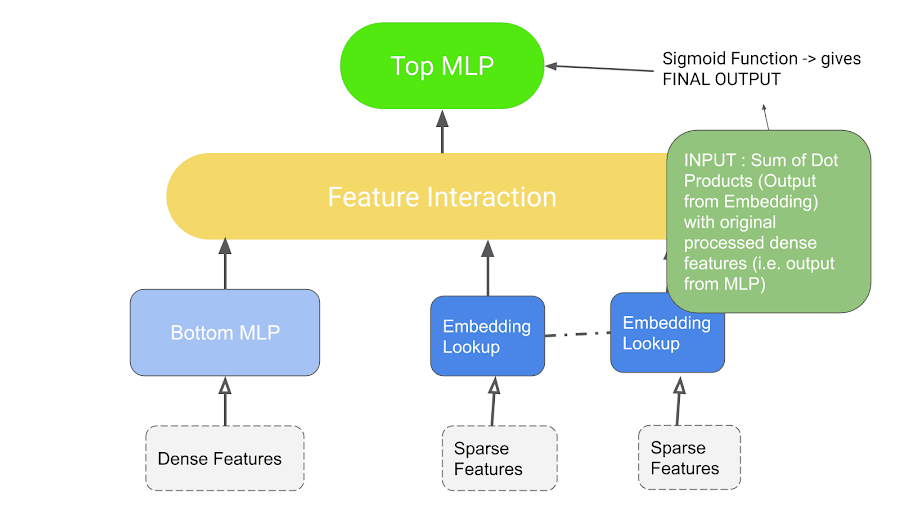
Source from: https://medium.com/swlh/deep-learning-recommendation-models-dlrm-a-deep-dive-f38a95f47c2c
All configurable parameters are outlined in blue, and the operators used are shown in Green.
Issues
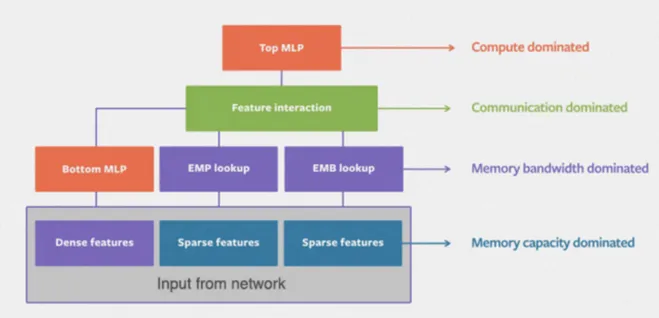
- Memory Capacity Dominated (Input from Network)
- Memory Band-Width Dominated (Processing of Features: Embedding Lookup and MLP)
- Communication Based (Interaction between Features)
- Compute Dominated (Compute/Run-Time Bottleneck)
1. Memory Capacity Dominated
-
Embeddings contribute the majority of parameters, with several tables each requiring excess of multiple GBs of memory. This necessitates Distribution of moels across Multiple Devices.
-
Data Parallelism is preferred for MLPs since this enables conurrent processing of samples on different devices and only requires communication when accumulating updates.
2. Memory Band-Width Dominated
-
Embedding Lookups can cause memory constraints.
-
Quotient-Remainder Trick
Using 2 complementary functions i.e. integer quotient and remainder functions: we can produce 2 separate embedding tables and combine them in a way that yields a unique embedding for each category.
3. Communication Based
DLRM uses model parallelism to avoid replicating the whole set of embedding tables on every GPU device and data parallelism to enable concurrent processing of samples in FC layers.
MLP parameters are replicated across GPU devices and not shuffled.
What is the problem?
Transferring embedding tables across nodes in a cluster becomes expensive and could be a Bottleneck.
Solution
Since it's the interaction between pairs of learned embedding vectors that matters and not the absolute values of embedding themselves.
We hypothesize we can learn embeddings in different nodes independently to result in a good model.
Saves Network Bandwidth by synchronizing only MLP parameters and learning Embedding tables independently on each of the server nodes.
4. Compute Dominated
- MLP also results in Compute Overload
- Co-location creates performance bottlenecks when running production-scale recommendation models leading to lower resource utilization
Solution: FBGEMM